Python 线性回归
title: Python 线性回归 icon: fas fa-list author: 周子力 order: 42 category:
- 教学文档 tag:
- Python
Python 线性回归
1.什么是线性回归?
线性回归分析(Linear Regression Analysis)是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。本质上说,这种变量间依赖关系就是一种线性相关性,线性相关性是线性回归模型的理论基础
所以线性的定义是:自变量之间只存在线性关系,即自变量只能通过相加、或者相减进行组合
二十世纪二十年代,开创量子力学的哥本哈根学派科学家波尔、海森伯认则为认为世界上一切事物的发生都是不确定的,只能用概率也就是发生的可能性来描述事物运动规律。也就是说世间一切的事儿都符合于某种概率分布而不是因果,可以用概率模型来表示一切规律
线性回归依然是工业界使用最广泛的模型。和学校项目及Kaggle不同的是,工业界尤其是大一点的互联网公司,除了NLP和CV方向,一般缺的不是数据而是算力。同时因为数据量够多,线性回归这种简单的模型也可以产生不错的效果。而使用更复杂的模型不仅速度会大幅下降,准确率也不见得能提高多少。在很多场景下,因为公司没办法根据黑盒模型去做相应的策略,所以业务方也更需要可解释性的模型,如线性回归,决策树,知识图谱等。站在决策者的角度,他们也很难在重大问题上去相信无法解释的模型。所以线性回归,依旧是工业界使用最广泛,效果非常好的模型
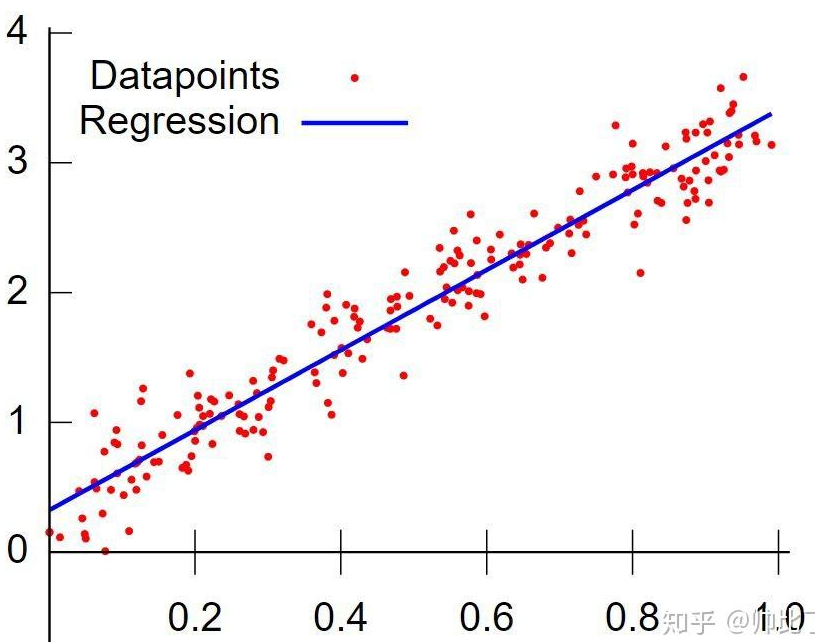
2.线性模型的基本形式
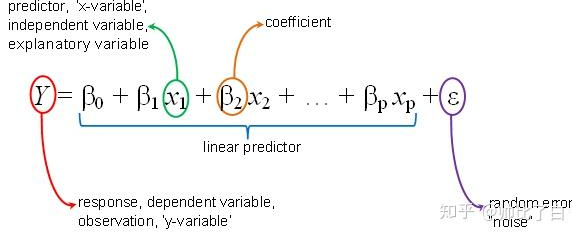
一般用向量形式可以写成:
为什么需要 b (Bias Parameter):类似于线性函数中的截距,在线性模型中补偿了目标值的平均值(在训练集上的)于基函数值的加权平均值之间的差距。即打靶打歪了,但是允许通过平易固定向量的方式移动到目标点上(每个预测点和目标点之间的偏置都必须是固定的)
3.预测与真实间的距离
使用MSE(均方误差),求使D最小时的w,d
- SSE(误差平方和)
- 欧式距离
- 曼哈顿距离
- 马式距离
- 其他距离(汉明距离,编辑距离)
4.建立目标函数
这里使用均方误差MSE来判定距离,并限定损失函数为平方损失函数,也就是普通最小二乘法(Ordinary Least Square,OLS),得到目标函数。其中“二乘”表示取平方,“最小”表示损失函数最小
通过调整参数使模型更加贴合真实数据
那么为什么用误差平方和来表示线性回归问题的损失函数?
这是因为线性回归有这样的假设,对于给定的 $ y^i $ 总能找到 使得这个等式成立 ,表示真实值和预测值之间的误差且服从正态分布
为什么要加: 是因为建模的时候不可能把所有可能性都考虑。因此把剩下的特征及噪声统一放到一起来考虑。
为什么误差要服从正态分布: 误差的产生有很多种因素的影响,误差可以看作是这些因素(随机变量)之和共同作用而产生的,由中心极限定理可知随机变量和的分布近似的服从正态分布 随机变量的概率密度函数为:
代入 则:
最小二乘法:所选择的回归模型应该使所有观察值的残差平方和达到最小,即采用平方损失函数
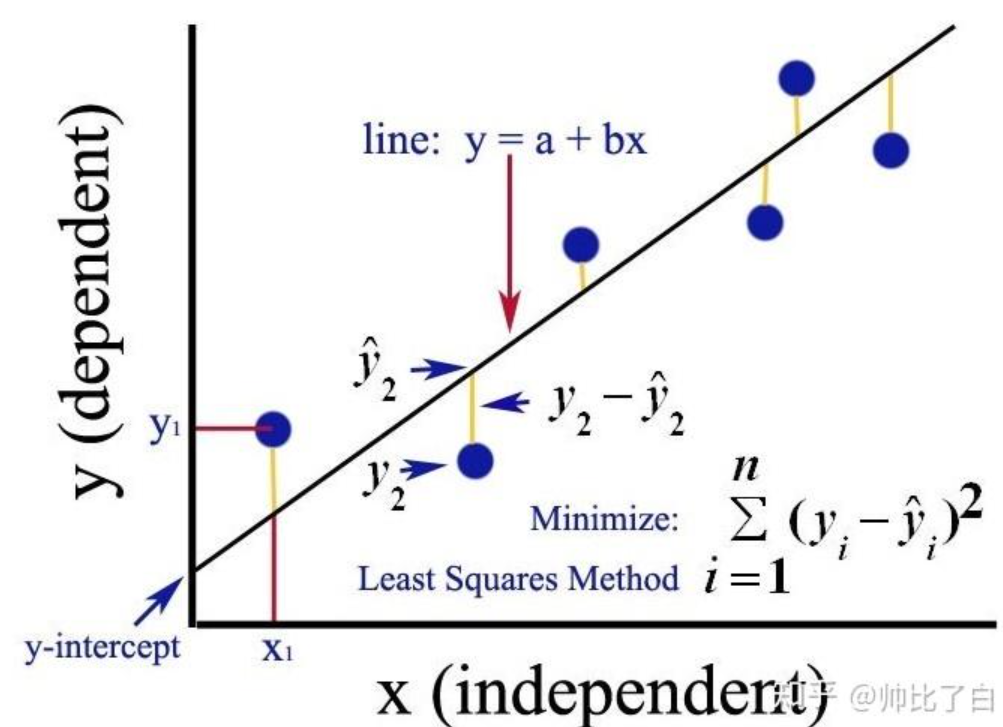
5.求解和b的参数
可以看出最小二乘法得到的是一个凸函数,可以看作一元二次方程,目标是求该方程的最小值,即求一元二次方程导数逼近0的点。介绍两种方法,一种通过矩阵运算得到精确解的方法,另一种在数据量巨大数据情况复杂时使用的逼近最优解的方法:梯度下降法
非线性的最小二乘可以通过牛顿高斯迭代、LM算法、梯度下降求解 梯度下降:随机初始化和b通过逼近的方式来求解
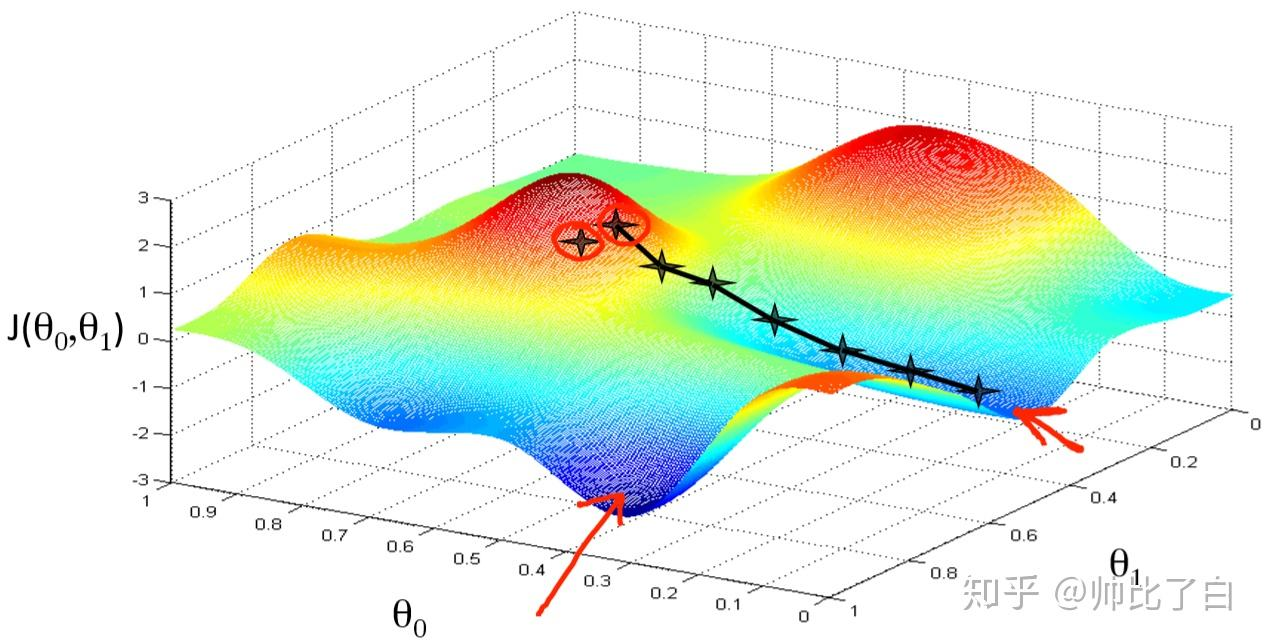
梯度下降形象解释: 把损失函数想象成一个山坡,目标是找到山坡最低的点。则随便选一个起点,计算损失函数对于参数矩阵在该点的偏导数,每次往偏导数的反向向走一步,步长通过 α\alpha\alpha 来控制,直到走到最低点,即导数趋近于0的点为止缺点:最小点的时候收敛速度变慢,并且对初始点的选择极为敏感梯度下降有时会陷入局部最优解的问题中,即下山的路上有好多小坑,运气不好掉进坑里,但是由于底部梯度(导数)也为0,故以为找到了山的底部同时,步长选择的过大或者过小,都会影响模型的计算精度及计算效率
6.sklearn实现线性回归
classs sklearn.linear_model.LinearRegression (fit_intercept=True, normalize=False, copy_x=True,n_jobs=None)

线性回归的类可能是我们目前为止学到的最简单的类,仅有四个参数就可以完成一个完整的算法。并且看得出,这些 参数中并没有一个是必填的,更没有对我们的模型有不可替代作用的参数。这说明,线 性回归的性能,往往取决于数 据本身,而并非是我们的调参能力,线性回归也因此对数据有着很高的要求。幸运的是,现实中大部分连续型变量之 间,都存在着或多或少的线性联系。所以线性回归虽然 简单,却很强大。
顺便一提,sklearn中的线性回归可以处理多标签问题,只需要在fit的时候输入多维度标签就可以了。
6.1案例
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#导入三大件
from sklearn.linear_model import LinearRegression as LR
#导入线性回归模型
from sklearn.model_selection import train_test_split
#导入划分训练集和测试集的模块
from sklearn.model_selection import cross_val_score
#导入交叉验证验证
from sklearn.datasets import fetch_california_housing as fch
#加利福尼亚房屋价值数据集
#导入数据,探索数据
house_value=fch()
#需要下载,导入
house_value.data.shape
#查看数据的维度
#建立datafram
X=pd.DataFrame(data=house_value.data,columns=house_value.feature_names)
# MedInc:该街区住户的收入中位数
# HouseAge:该街区房屋使用年代的中位数
# AveRooms:该街区平均的房间数目
# AveBedrms:该街区平均的卧室数目
# Population: 街区人口
# AveOccup: 平均入住率
# Latitude: 街区的纬度
# Longitude:街区的经度
X.describe()
y=house_value.target
#y是房价的标签
y.max()
y.min()
#查看y的最大最小值
#数据有量纲的问题,我们应该对数据进行标准化
from sklearn.preprocessing import StandardScaler
standard= StandardScaler()
#实例化标准化的类
standard.fit(X)
#传入X
trans_data=pd.DataFrame(standard.transform(X))
#标准化三部曲
trans_data.head()
#查看数据
#分训练集和测试集
X_train,X_test,Y_train,Y_test=train_test_split(trans_data,y,test_size=0.3,random_state=420)
#恢复索引
for i in [X_train, X_test]:
i.index = range(i.shape[0])
#建模,无需设置参数,默认normalize=False,同学可自行尝试normalize=True,看对结果是佛会有影响。
reg = LR().fit(X_train, Y_train)
y_hat = reg.predict(X_test)
##建模并训练,预测,得到y_hat。
y_hat.min()
y_hat.max()
reg.coef_
#查看模型的系数w
reg.intercept_
#查看截距项w0
[*zip(X.columns,reg.coef_)]
#将系数和特征对应
# MedInc:该街区住户的收入中位数
# HouseAge:该街区房屋使用年代的中位数
# AveRooms:该街区平均的房间数目
# AveBedrms:该街区平均的卧室数目
# Population: 街区人口
# AveOccup: 平均入住率
# Latitude: 街区的纬度
# Longitude:街区的经度
7. 回归类模型的评估指标
回归类算法的模型评估一直都是回归算法中的一个难点,但不像我们曾经讲过的无监督学习算法中的轮 廓系数等等评 估指标,回归类与分类型算法的模型评估其实是相似的法则——找真实标签和预测值的 差异。只不过在分类型算法 中,这个差异只有一种角度来评判,那就是是否预测到了正确的分类,而 在我们的回归类算法中,我们有两种不同的 角度来看待回归的效果: 第一,我们是否预测到了正确的数值。 第二,我们是否拟合到了足够的信息。 这两种角度,分别对应着不同的模型评估指标。
7.1 是否预测了正确的值
RSS残差平方和的本质是我们的预测值与真实值之间的差异,也就是从第一种角度 来评估我们回 归的效力,所以RSS既是我们的损失函数,也是我们回归类模型的模型评估指标之一。但是,RSS有着致命的缺点:它是一个无界的和,可以无限地大。我们只知道,我们想要求解最小的 RSS,从RSS的公式来看,它不能为负,所以 RSS越接近0越好,但我们没有一个概念,究竟多小才算好,多接近0才算好?为了应对这种状况,sklearn中使用RSS 的变体,均方误差MSE(mean squared error)来衡量我们的预测值和真实值的差异:
均方误差,本质是在RSS的基础上除以了样本总量,得到了每个样本量上的平均误差。有了平均误差,我们就可以将 平均误差和我们的标签的取值范围在一起比较,以此获得一个较为可靠的评估依据。在 sklearn当中,我们有两种方式: 调用这个评估指标: 1.是使用sklearn专用的模型评估模块metrics里的类mean_squared_error。 2.是调用交叉验证的类cross_val_score并使用里面的scoring参数来设置使用均方误差。
from sklearn.metrics import mean_squared_error as MSE
#导入均方误差
MSE(y_hat,Y_test)
#得到误差
Y_test.mean()
#查询测试集的y平均值
cross_val_score(reg,trans_data,y,cv=10,scoring="neg_mean_squared_error").mean()
#交叉验证(模型,特征,标签,k折,SKlearn中用负均方误差)
7.2是否拟合了足够的信息
对于回归类算法而言,只探索数据预测是否准确是不足够的。除了数据本身的数值大小之外,我们还希望我们的模型 能够捕捉到数据的”规律“,比如数据的分布规律,单调性等等,而是否捕获了这些信息并 无法使用MSE来衡量。 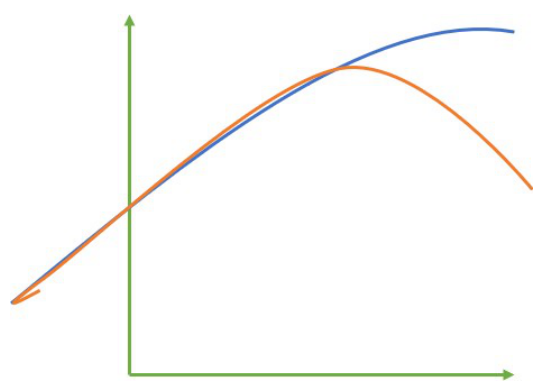
来看这张图,其中红色线是我们的真实标签,而蓝色线是我们的拟合模型。这是一种比较极端,但的确可能发生的情况。这张图像上,前半部分的拟合非常成功,看上去我们的真实标签和我们的预测结果几乎重合,但后半部分的拟合 却非常糟糕,模型向着与真实标签完全相反的方向去了。对于这样的一个拟合模型,如果我们使用MSE来对它进行判断,它的MSE会很小,因为大部分样本其实都被完美拟合了,少数样本的真实值和预测值的巨大差异在被均分到每个样本上之后,MSE就会很小。但这样的拟合结果必然不是一个好结果,因为一旦我的新样本是处于拟合曲线的后半段的,我的预测结果必然会有巨大的偏差,而这不是我们希望看到的。所以,我们希望找到新的指标,除了判断预测的数值是否正确之外,还能够判断我们的模型是否拟合了足够多的,数值之外的信息。我们使用方差来衡量数据上的信息量。如果方差越大,代表数据上的信息量越多,而这个信息量不仅包括了数值的大小,还包括了我们希望模型捕捉的那些规律。为了衡量模型对数据上的信息量的捕捉,我们定义了来帮助我们, 越接近1越好。
参考
https://zhuanlan.zhihu.com/p/147297924