装载问题
大约 7 分钟教学文档回溯算法
题目描述
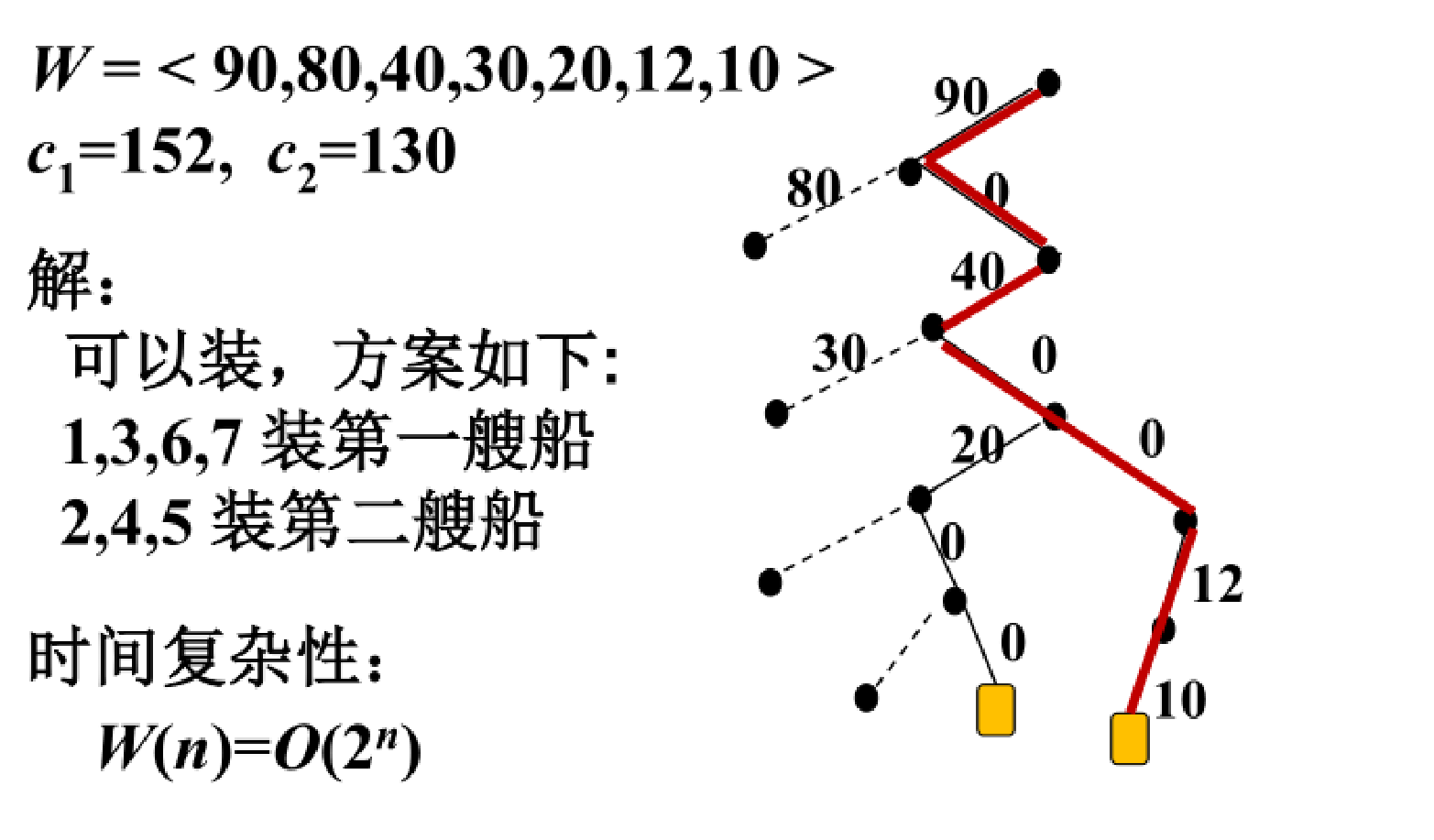
解题思路
解题思路
该代码使用**带上界剪枝的宽度优先搜索(BFS)**来求解单船装载问题。核心思想如下:
问题建模:将装载问题视为0-1背包问题,每个集装箱有两个选择(装/不装),目标是在不超过船容量的前提下使总重量最大。
BFS搜索框架:
- 使用队列存储状态
(level, current_weight),其中level表示当前处理到第几个集装箱(从0开始),current_weight表示当前已装载的总重量。 - 从根节点
(0, 0)开始,逐层扩展决策树。
- 使用队列存储状态
上界剪枝优化:
- 预处理后缀和数组
bounds:bounds[i]表示从第i个集装箱到最后一个集装箱的总重量(即weights[i] + weights[i+1] + ... + weights[n-1])。 - 剪枝条件:对于当前状态
(level, current_weight),计算其理论最大可能重量current_weight + bounds[level](即当前重量加上剩余所有集装箱重量)。 - 仅当理论最大值大于当前已知最优解
max_weight时,才将该分支加入队列继续搜索,否则剪枝。
- 预处理后缀和数组
搜索过程:
- 对每个状态,尝试装入当前集装箱(若不超重)和不装入两种选择。
- 在装入操作时更新全局最优解
max_weight。 - 利用上界剪枝避免探索不可能产生更优解的分支。
代码实现
宽度优先搜索(BFS)
import queue
def fun(weights,capacity):
max_weight=0
n=len(weights)
pq=queue.Queue()
pq.put((0,0))
while not pq.empty():
level,current_weight=pq.get()
if level==n:
continue
if current_weight+weights[level]<=capacity:
temp_weight=current_weight+weights[level]
max_weight=max(max_weight,temp_weight)
pq.put((level+1,temp_weight))
pq.put((level+1,current_weight))
return max_weight
weights =[90,80,40,30,20,12,10]# [2, 3, 4, 5] # Weights of the items
capacity = 152#8 # Capacity of the ship
# weights =[2, 3, 4, 5] # Weights of the items
# capacity =8 # Capacity of the ship
result = fun(weights, capacity)
print("Maximum weight that can be loaded:", result)
带上界剪枝的宽度优先搜索(BFS)
import queue
def fun2(weights,capacity):
max_weight=0
n=len(weights)
pq=queue.Queue()
pq.put((0,0))#first level,second,weight
bounds=[0]*(n+1)
for i in range(n-1,-1,-1):
bounds[i]=bounds[i+1]+weights[i]
print(i,bounds[i])
while not pq.empty():
level,current_weight=pq.get()
if level==len(weights):
continue
if current_weight+weights[level]<=capacity:
temp_weight=current_weight+weights[level]
max_weight=max(max_weight,temp_weight)
if temp_weight+bounds[level+1]>max_weight:
pq.put((level+1,temp_weight))
if current_weight+bounds[level+1]>max_weight:
pq.put((level+1,current_weight))
return max_weight
weights =[90,80,40,30,20,12,10]# [2, 3, 4, 5] # Weights of the items
capacity = 152#8 # Capacity of the ship
# weights =[2, 3, 4, 5] # Weights of the items
# capacity =8 # Capacity of the ship
result = fun2(weights, capacity)
print("Maximum weight that can be loaded:", result)
最优优先搜索
import heapq
def fun(weights, capacity):
n = len(weights)
if n == 0 or capacity <= 0:
return 0
# 预处理后缀和:bounds[i] = weights[i] + ... + weights[n-1]
bounds = [0] * (n + 1)
for i in range(n - 1, -1, -1):
bounds[i] = bounds[i + 1] + weights[i]
# 最大堆:存储 (-bound, level, current_weight)
# 用负值模拟最大堆(因为 heapq 是最小堆)
max_heap = [(-bounds[0], 0, 0)] # 初始上界是所有物品总和
max_weight = 0
while max_heap:
neg_bound, level, current_weight = heapq.heappop(max_heap)
bound = -neg_bound
# 剪枝:如果上界不超过当前最优解,跳过
if bound <= max_weight:
continue
# 到达叶节点
if level == n:
max_weight = max(max_weight, current_weight)
continue
w = weights[level]
# 选择:装入当前物品(若不超载)
if current_weight + w <= capacity:
new_weight = current_weight + w
max_weight = max(max_weight, new_weight) # 及时更新最优解
new_bound = new_weight + bounds[level + 1]
if new_bound > max_weight:
heapq.heappush(max_heap, (-new_bound, level + 1, new_weight))
# 不选择:不装入当前物品
new_weight = current_weight
new_bound = new_weight + bounds[level + 1]
if new_bound > max_weight:
heapq.heappush(max_heap, (-new_bound, level + 1, new_weight))
return max_weight
# 测试
weights = [90, 80, 40, 30, 20, 12, 10]
capacity = 152
result = fun(weights, capacity)
print("Maximum weight that can be loaded:", result)
🚨 注意事项
1. 状态表示要清晰
- 在 BFS 中,每个节点应明确记录:当前处理到第几个物品、当前总重量、以及可选地记录所选物品列表。
- 若只记录
(level, weight),虽然节省空间,但无法回溯具体方案;若需输出方案,必须携带选择路径。
✅ 建议:根据需求决定是否存储
selected_items列表。
2. 剪枝条件必须严谨
- 上界剪枝(如
current_weight + bounds[level] > max_weight)是性能关键,但必须确保:- 上界计算准确(后缀和
bounds[i]必须包含从i开始的所有剩余重量) - 剪枝判断逻辑不能漏掉合法最优解
- 避免因浮点误差或整数溢出导致错误剪枝(本题为整数,无此风险)
- 上界计算准确(后缀和
⚠️ 特别注意:不要在“装入”操作前剪枝,因为即使当前重量+剩余重量 > 最优解,也可能通过“不装入”某些大件物品来达到更优解——但在本算法中,由于我们是从左到右顺序决策,且上界是“剩余所有”,因此该剪枝是安全的。
3. 边界情况处理
- 空物品列表 → 返回 0
- 所有物品都超重 → 返回 0
- 容量为 0 → 返回 0
- 单个物品刚好等于容量 → 应能正确识别
✅ 测试用例建议覆盖以上极端情况。
4. 队列实现与性能
- Python 的
queue.Queue()是线程安全的,但效率略低于collections.deque。 - 对于纯算法题,推荐使用
from collections import deque,其popleft()和append()操作时间复杂度为 O(1)。
✅ 改进建议:
from collections import deque
q = deque()
q.append((0, 0))
...
level, weight = q.popleft()
5. 叶节点更新缺失问题
- 如之前分析,在
level == n时直接continue,可能遗漏未被“装入”动作更新的合法解(尽管在实践中不会发生,因为所有非零重量都来自“装入”操作)。 - 健壮性建议:显式处理叶节点:
if level == n:
max_weight = max(max_weight, current_weight)
continue
6. 变量命名与代码可读性
pq易被误解为“优先队列”,实际是普通 FIFO 队列 → 建议改名为bfs_queue或qbounds可考虑命名为suffix_sum或remaining_weight以增强语义
✅ 好的命名 = 自文档化代码
7. 内存爆炸风险
- BFS 在最坏情况下会生成 2^n 个状态,当 n > 20 时内存和时间开销剧增。
- 实际应用中,n 较大时应改用动态规划或分支限界法。
💡 提示:对于
n=30,2^30 ≈ 10亿状态,不可行!
💡 启发与延伸思考
1. 算法思想迁移
- 装载问题本质是 0-1 背包问题,BFS + 剪枝是一种“暴力优化”思路。
- 类似方法可用于:
- 子集和问题(Subset Sum)
- 最大独立集(图论)
- TSP(旅行商问题)的部分解空间搜索
✅ 启发:任何具有“决策树结构”的组合优化问题,都可以尝试 BFS + 剪枝。
2. 剪枝策略的通用性
- “上界剪枝”(Upper Bound Pruning)是分支限界法的核心思想。
- 可扩展为:
- 下界剪枝(Lower Bound Pruning):用于最小化问题
- 可行性剪枝:提前排除不可能满足约束的分支
- 支配剪枝:若一个状态被另一个状态“支配”(更优),则剪掉
✅ 启发:剪枝不是魔法,而是对问题结构的深刻理解。
3. 动态规划 vs BFS 剪枝
- DP 优势:时间复杂度 O(n × capacity),适合容量较小的情况
- BFS 剪枝优势:可输出具体方案、易于并行化、适用于容量极大或非数值约束的问题
✅ 启发:没有“最好”的算法,只有“最适合”的算法。根据数据规模和需求选择。
4. 启发式搜索的桥梁
- BFS + 上界剪枝 是向 A 搜索* 或 分支限界法 迈进的第一步。
- 若将“当前重量 + 剩余最大可能重量”作为启发函数,即可构建 A* 搜索框架。
✅ 启发:掌握基础算法,是通向高级算法的阶梯。
5. 工程实践中的权衡
- 在竞赛或面试中,BFS + 剪枝常用于小规模数据(n ≤ 20)。
- 在工业级系统中,应优先考虑 DP、贪心、近似算法或混合方法。
✅ 启发:算法选择要考虑“精度、速度、内存、可维护性”四维平衡。
🎯 总结一句话:
BFS 解装载问题是“暴力美学”的体现 —— 用空间换时间,用剪枝降复杂度,用结构化思维驾驭指数爆炸的解空间。
掌握它,不仅解决一道题,更是打开组合优化世界的大门。